Data warehouse design involves principles that pertain to the layout of the warehouse and its components, as well as the way the data is stored and accessed. In its most basic form, data warehouse design follows the Extract-Transform-Load method, or ETL. In this method, the data is extracted from its source, then transformed into a usable form, and finally loaded into the warehouse. For a comprehensive data warehouse design, the following principles must be followed: Data Governance: Data governance is the process of managing data in the warehouse. It includes processes for authorizing access to the data, for approving changes to the data, and for ensuring the accuracy and integrity of the data over time. This is a crucial step that must be completed prior to the other design components. Data Modeling: Data modeling refers to the way the data is structured within the warehouse. This includes the creation of logical and physical models of the data, as well as entities, relationships, and hierarchies. Careful data modeling ensures that the data can be accessed quickly and accurately. Data Integration: The warehouse must be designed to integrate data from various sources, including both external sources (such as APIs) and internal sources (such as databases). Data integration is necessary to ensure that the data is consistent and usable across all sources. Data Quality Assurance: Data quality assurance is an ongoing process that ensures that the data in the warehouse is accurate, complete, and up-to-date. This includes processes for verifying the accuracy of data as it is entered into the warehouse, as well as procedures for maintaining the integrity of the data over time.Data Warehouse Design Principles



Data Warehouse Design Principles





Data warehouse design is not a one-time activity; it is an ongoing process that involves constant review, modification, and optimization. To ensure the success of the data warehouse design process, it is important to follow best practices such as: Data Warehouse Management: The data warehouse should be managed to ensure that the data is secure, accurate, and up-to-date. This includes regular maintenance activities such as backups, monitoring, and indexing. Data Warehouse Security: The security of the data in the warehouse should be a top priority. This includes implementing access controls, encryption, and other security measures to protect the data. Data Warehouse Performance: Performance is a key concern when designing a data warehouse. Best practices for optimizing performance include using the optimal hardware, storage, and query strategies. Data Warehouse Automation: To ensure efficient workflow, the design process should include features such as automated data extraction, transformation, and loading. This ensures that the warehouse is always running at peak performance.Data Warehouse Design Best Practices

Data Warehouse Design Best Practices



Before beginning the data warehouse design process, it is important to consider the architecture of the warehouse. The architecture of the data warehouse is the foundation of the design, and it must be carefully thought out in order to achieve a successful data warehouse design. The key considerations for data warehouse architecture design include: Data Sources: Data sources will vary depending on the type of data warehouse. These sources may include databases, flat files, and APIs, and the architecture must account for these sources and the ways the data can be stored and accessed. Data Structures: Data structures must be determined in order to effectively store and access the data. Common data structures for a data warehoues are star schemas, snowflake schemas, and object-oriented databases. Data Storage: The architecture of the data warehouse must consider the types of data that will be stored and how the data will be stored. Common storage solutions for a data warehouse include relational databases, multi-dimensional databases, MapReduce, and Hadoop. Data Access: The architecture must consider how data will be accessed, including who will have access to the data and what queries will be used to access the data.Data Warehouse Architecture Design

Data Warehouse Architecture Design



Data warehouse design and optimization involve the refinement of the data warehouse design to ensure that it meets the needs of the organization. This includes optimizing the architecture, the data structures, the data storage, and the data access. Optimization activities may include indexing, caching, partitioning, and denormalization. The optimization process must be carefully monitored and reviewed to ensure that the changes do not negatively affect the performance of the data warehouse. Indexing: Indexing optimizes the retrieval of data by creating indexes on commonly used columns. This allows the data to be retrieved quickly without having to search through the entire dataset. Caching: Caching is the process of storing commonly accessed data in memory to reduce the amount of time needed to retrieve the data. This makes data retrieval much faster. Partitioning: Partitioning optimizes the data storage by dividing the data into smaller, more manageable chunks. This makes the data easier to manage and easier to query. Denormalization: Denormalization is a process of simplifying the data structure in order to improve performance. This can be done by combining multiple tables into a single table, by adding extra columns, or by creating specialized views of the data.Data Warehouse Design and Optimization


Data Warehouse Design and Optimization

Modern data warehouse design has evolved due to the advent of cloud computing, big data, and analytics. To accommodate these changes, modern data warehouse designs must include features such as data virtualization, data lakes, and cloud analytics. Data virtualization allows distributed data to be accessed and used in real-time, while data lakes enable organizations to manage large datasets. Cloud analytics technologies provide faster processing, reduce costs, and enable faster decision-making. Data Virtualization: Data virtualization is the process of accessing and using data from multiple sources in real-time. This allows organizations to quickly access and utilize data without the need to physically store it. Data Lakes: Data lakes enable organizations to store large datasets and quickly access and analyze the data. This is useful for organizations dealing with big data, as it allows for large amounts of data to be quickly accessed and analyzed. Cloud Analytics: Cloud analytics provide a cost-effective way to process large amounts of data. These technologies can be used to quickly analyze data and generate insights from large datasets.Modern Data Warehouse Design


Modern Data Warehouse Design





Data warehouse design patterns are design principles and best practices that are applicable to data warehousing projects. These patterns are used to develop standardized data models that can be applied to various projects. Common design patterns for data warehouses include the Entity-Relationship pattern, the Data Vault pattern, and the Star Schema pattern. Each of these patterns has its own advantages and disadvantages, and should be carefully considered when designing a data warehouse. Entity-Relationship Pattern: The Entity-Relationship Pattern is a widely-used data modeling technique that focuses on the relationships between entities. It can be used to define and design data models that represent the entities and their relationships in the data warehouse. Data Vault Pattern: The Data Vault pattern is a data modeling technique that focuses on data integrity, scalability, and robustness. It is designed to represent the source data and enable easy tracking of changes over time. Star Schema Pattern: The Star Schema pattern is a data modeling technique that focuses on simplicity and performance. It is designed to simplify the data model and make the data more accessible.Data Warehouse Design Patterns

Data Warehouse Design Patterns

Designing a data warehouse for a big data architecture requires careful consideration of the architecture, the data structures, the data storage, and the data access. Modern big data architectures emphasize scalability, flexibility, and performance, and the data warehouse must be designed with these objectives in mind. The key design considerations for a big data architecture include: Scalable Data Model: The data model must be designed to scale as the data grows, without causing any performance degradation. This includes using techniques such as denormalization and partitioning. Distributed Storage: The data should be stored on distributed storage solutions such as HDFS and NoSQL databases. This allows for scalability and flexibility in storage and access. Data Access: The data warehouse must be designed to facilitate easy access to the data. This includes providing high-speed access to data, as well as the ability to query data from multiple sources. Data Analytics: The data warehouse must be designed to facilitate the analysis of data. This includes providing access to predictive analytics, machine learning algorithms, and other advanced analytics tools.Data Warehouse Design for Big Data Architecture
Data Warehouse Design for Big Data Architecture





Business intelligence (BI) requires a different type of data warehouse design than traditional data warehousing. BI requires the ability to quickly and accurately analyze data, and the data warehouse must be designed to facilitate this. The key design considerations for BI include: Data Storage: BI relies on OLAP (online analytical processing) technologies such as cubes and multidimensional databases. These technologies provide fast analytics and allow for the efficient retrieval of data for BI purposes. Data Access: The data warehouse must be designed to enable easy access to the data. This includes providing access to dimensional data models, as well as allowing for data to be accessed and queried from multiple sources. Data Visualization: The data warehouse should be designed with data visualization in mind. This includes providing advanced visualization tools such as dashboards and charts. Data Cleansing: Data warehouses must be regularly checked for accuracy and validity. This includes processes for verifying the accuracy of data as it is entered into the warehouse, as well as procedures for maintaining the integrity of the data over time.Data Warehouse Design for Business Intelligence

Data Warehouse Design for Business Intelligence


Hypercube analysis requires a different type of data warehouse design than traditional data warehousing. Hypercube analysis requires the ability to quickly and accurately analyze large amounts of data, and the data warehouse must be designed to facilitate this. The key design considerations for hypercube analysis include: Data Structures: Hypercube analysis requires data structures such as cubes, star schemas, and snowflake schemas. These structures provide an efficient way to store and query large amounts of data. Data Access: The data warehouse must be designed to enable efficient access to the data. This includes providing access to data cubes, as well as allowing for data to be queried from multiple sources. Data Aggregation: The data warehouse should be designed to support efficient data aggregation. This includes aggregate functions, data compression, and summary tables. Data Filtration: The data warehouse should be designed to allow filtering of data. This includes indexing, views, and query optimization techniques such as bloom filters and hash functions.Data Warehouse Design for Hypercube Analysis


Data Warehouse Design for Hypercube Analysis

Mart tables are specialized tables used for data warehousing and data analysis. Designing a data warehouse for mart tables requires careful consideration of the data structures, the data storage, and the data access. The key design considerations for mart tables include: Data Structures: Mart tables must be designed to facilitate easy access to the data. This includes the creation of logical and physical models of the data, as well as entities, relationships, and hierarchies. Data Storage: The mart tables should be stored on a relational database and implemented using a star schema or snowflake schema. This ensures that the data can be accessed efficiently and that the data is normalized. Data Access: The data warehouse must be designed to enable easy access to the data. This includes providing access to dimensional data models, as well as allowing for data to be queried from multiple sources. Data Transformation: The data warehouse should be designed to allow for data transformation. This includes custom transformation functions, data cleansing processes, and ETL processes.Data Warehouse Design for Mart Tables


Data Warehouse Design for Mart Tables



Data warehouse strategy and design involve the development of the overall strategy for the data warehouse and the development of the design for the data warehouse. Before beginning the design process, it is important to consider the goals and objectives of the data warehouse. Common objectives include scalability, performance, data integrity, security, and cost-effectiveness. The design process should include a wide range of best practices, including data governance, data integration, data quality assurance, and performance optimization. Data Governance: Data governance is the process of managing data in the warehouse. It includes processes for authorizing access to the data, for approving changes to the data, and for ensuring the accuracy and integrity of the data over time. Data Integration: The warehouse must be designed to integrate data from various sources, including both external sources (such as APIs) and internal sources (such as databases). Data integration is necessary to ensure that the data is consistent and usable across all sources.Data Warehouse Strategy and Design
Data Warehouse Strategy and Design




Careful Consideration of Dataware House Design
 When it comes to designing and developing a
datawarehouse
, careful consideration is key for successful implementation. All aspects of warehouses must be taken into account from both a technical and functional point of view, including the transactional and conceptual design. This involves a set of activities aimed at structuring the data and transforming them into useful information.
From the
technical
viewpoint, it is important to define a suitable architecture that allows for easy query and adequate synchronization of data. As part of the overall architecture, use of techniques such as star-schemas, normalization, data reduction and denormalization should be appropriate to help reduce size, increase rpm and create efficient access to data. Also, it is important to validate the data prior to introduction into the datawarehouse, to ensure that no errors are introduced and data is consistent.
The
functional
design of the datawarehouse is crucial to identify all the user data requirements and how these need to be mapped to the design. User requirements may involve multiple forms of analysis, such as cross sectional, historical or predictive and will determine how the data is presented. Once these requirements have been established, much of this work will already have been done to ensure consistency in format, security and access.
To ensure long-term success, it's also important to make sure the datawarehouse is updated often. Using techniques such as ETL, changes to data as well as new data can be extracted from multiple source systems and loaded into the datawarehouse. This ensures that the datawarehouse is always current and reflecting the latest requirements and data.
When it comes to designing and developing a
datawarehouse
, careful consideration is key for successful implementation. All aspects of warehouses must be taken into account from both a technical and functional point of view, including the transactional and conceptual design. This involves a set of activities aimed at structuring the data and transforming them into useful information.
From the
technical
viewpoint, it is important to define a suitable architecture that allows for easy query and adequate synchronization of data. As part of the overall architecture, use of techniques such as star-schemas, normalization, data reduction and denormalization should be appropriate to help reduce size, increase rpm and create efficient access to data. Also, it is important to validate the data prior to introduction into the datawarehouse, to ensure that no errors are introduced and data is consistent.
The
functional
design of the datawarehouse is crucial to identify all the user data requirements and how these need to be mapped to the design. User requirements may involve multiple forms of analysis, such as cross sectional, historical or predictive and will determine how the data is presented. Once these requirements have been established, much of this work will already have been done to ensure consistency in format, security and access.
To ensure long-term success, it's also important to make sure the datawarehouse is updated often. Using techniques such as ETL, changes to data as well as new data can be extracted from multiple source systems and loaded into the datawarehouse. This ensures that the datawarehouse is always current and reflecting the latest requirements and data.
Datawarehouse Design Strategies
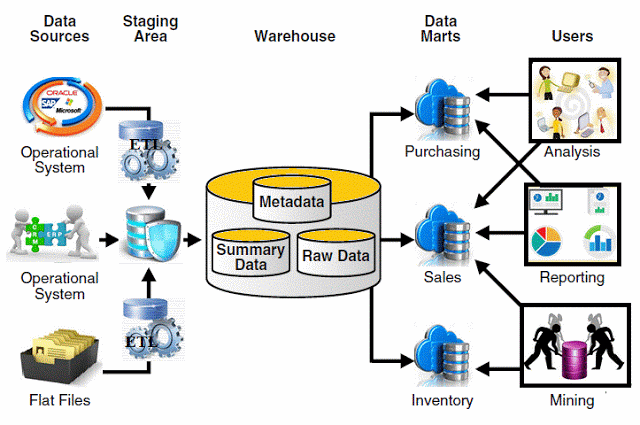 When considering the design of the datawarehouse, it is important to first decide what data is needed and how it will be stored. Depending on the use case, the data can be stored in relational databases, document databases, or text files. It is also important to understand the data sources and their characteristics, in order to better fit them into the datawarehouse.
Once the data sources are understood, it is important to consider how the data will be integrated, stored and extracted, while creating the right level of security for the data. For example, integration of data from disparate source systems can be achieved using Extract, Transform and Load (ETL) tools. This will streamline the process as well as help maintain data integrity. It is also important to ensure the data is properly secured and access is adequately controlled. With respect to data extraction, it is important to determine how the data warehouse will be used and how access needs to be made available according to user roles.
When considering the design of the datawarehouse, it is important to first decide what data is needed and how it will be stored. Depending on the use case, the data can be stored in relational databases, document databases, or text files. It is also important to understand the data sources and their characteristics, in order to better fit them into the datawarehouse.
Once the data sources are understood, it is important to consider how the data will be integrated, stored and extracted, while creating the right level of security for the data. For example, integration of data from disparate source systems can be achieved using Extract, Transform and Load (ETL) tools. This will streamline the process as well as help maintain data integrity. It is also important to ensure the data is properly secured and access is adequately controlled. With respect to data extraction, it is important to determine how the data warehouse will be used and how access needs to be made available according to user roles.
Conclusion
 The design of a successful datawarehouse is a complex undertaking and is essential to enable analytics and data-driven decision making. It requires careful consideration of both technical and functional aspects, as well as defining strategies for integration, storage, and extraction of data with adequate security access to the data. A well-designed datawarehouse can provide reliable, real-time data that will allow businesses to move quickly and accurately.
The design of a successful datawarehouse is a complex undertaking and is essential to enable analytics and data-driven decision making. It requires careful consideration of both technical and functional aspects, as well as defining strategies for integration, storage, and extraction of data with adequate security access to the data. A well-designed datawarehouse can provide reliable, real-time data that will allow businesses to move quickly and accurately.



:max_bytes(150000):strip_icc()/Porch-Den-DeSoto-Hardwood-Suede-Queen-Size-Futon-Sofa-Bed-e1e117db-7ed1-443e-b60f-98876730014c-3ea03957bf6c4feeab8aadcdaeaf61c5.jpg)


